
Resources
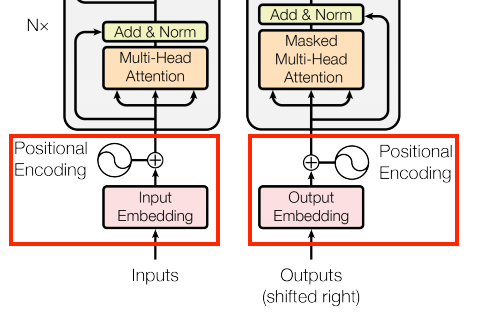
Positional Encoding
Positional encoding is used to provide a relative position for each token or word in a sequence. When reading a sentence, each word is dependent on the words around it. For instance, some words have different meanings in different contexts, so a model should be able to understand these variations and the words that each relies on for context.
May 8, 2023

Transformer’s Positional Encoding
How Does It Know Word Positions Without Recurrence?
In 2017, Vaswani et al. published a paper titled Attention Is All You Need for the NeurIPS conference. They introduced the original transformer architecture for machine translation, performing better and faster than RNN encoder-decoder models, which were mainstream at that time. Then, the big transformer model achieved SOTA (state-of-the-art) performance on NLP tasks.
October 30, 2021
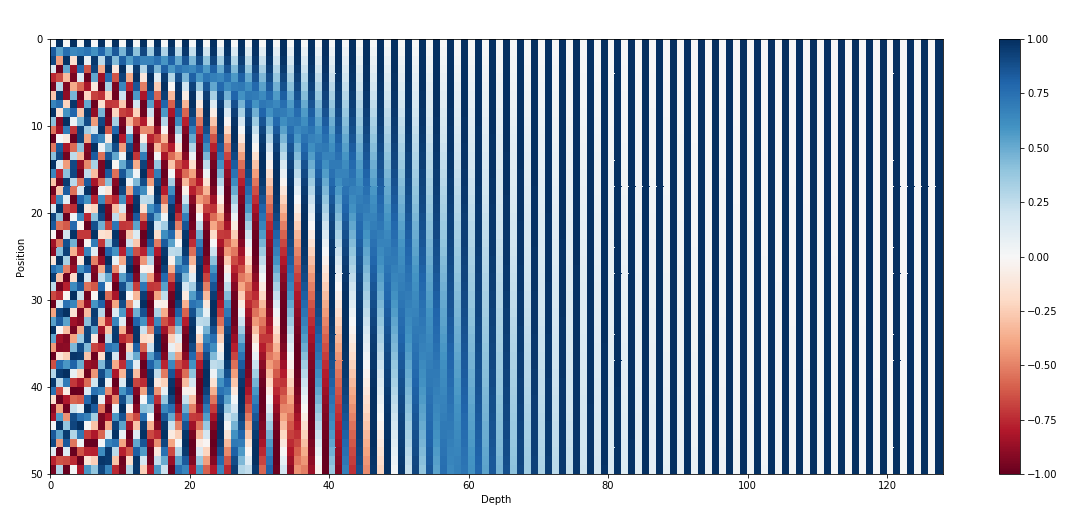
Transformer Architecture: The Positional Encoding
Let's use sinusoidal functions to inject the order of words in our model
Transformer architecture was introduced as a novel pure attention-only sequence-to-sequence architecture by Vaswani et al. Its ability for parallelizable training and its general performance improvement made it a popular option among NLP (and recently CV) researchers.
September 20, 2019
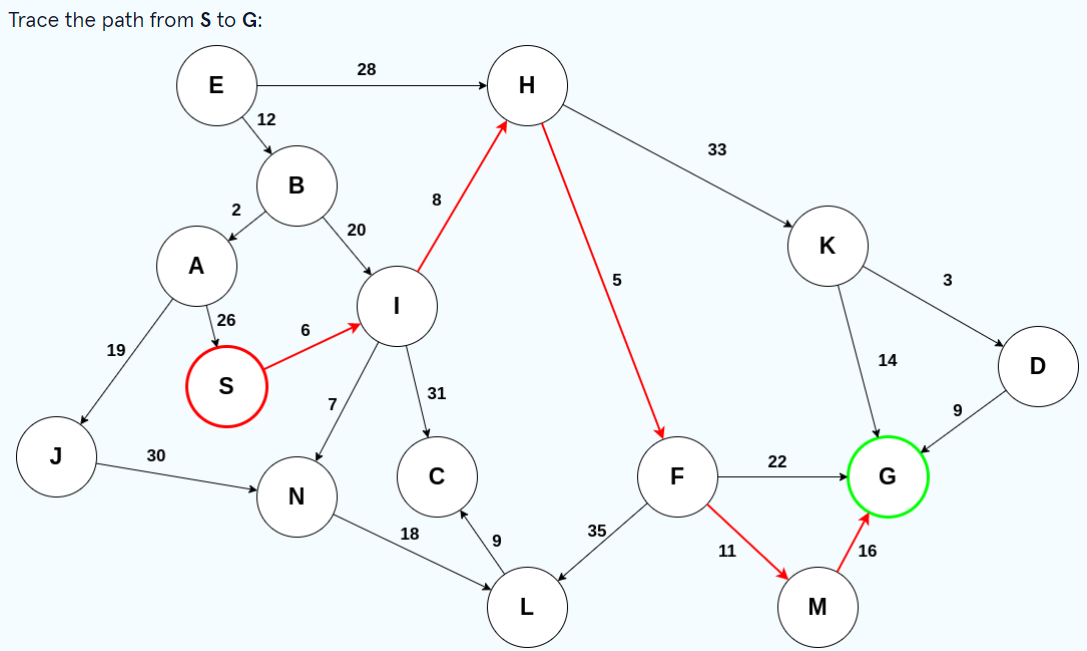
BEAM Search
BEAM Search, a variant of breadth-first Search, is an algorithm that searches a weighted graph for an optimal path from some start node S to some goal node G. The difference between BEAM search and breadth-first search is that at every level of the search tree, only the top β candidates are chosen for further exploration. Here, β is known as the beam width. The reasoning behind this is that a path from S to G is likely to pass through some top number of most promising nodes.
Jun 5, 2023
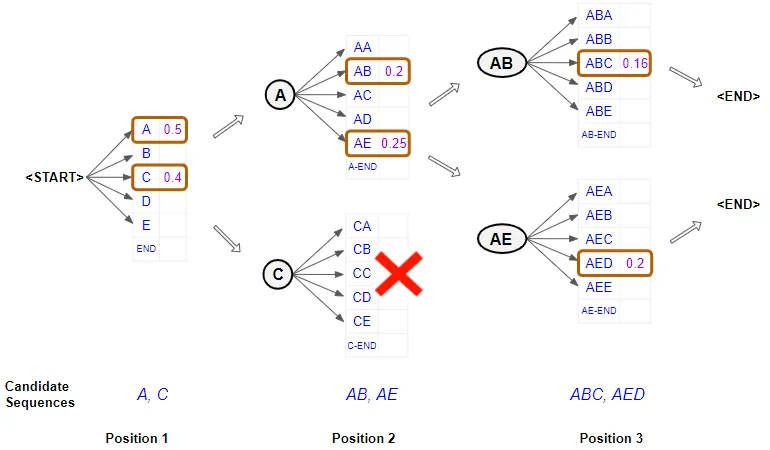
Foundations of NLP Explained Visually: Beam Search, How It Works
Many NLP applications such as machine translation, chatbots, text summarization, and language models generate some text as their output. In addition applications like image captioning or automatic speech recognition (ie. Speech-to-Text) output text, even though they may not be considered pure NLP applications.
April 1, 2021
Unmasking BERT: The Key to Transformer Model Performance
It seems clear that at the moment, practice is far ahead of theory in the technological life cycle of Deep Learning for NLP. We’re using approaches like masking which seem to work, and we fiddle with the numbers a bit and it works a little better or a little worse. Yet we can’t fully explain why that happens! Some people may find this frustrating and disappointing. If we can’t explain it, then how can we use it?
August 18, 2023
In-depth Understanding of LoRa and Finetuning a LLM using LoRa
With all the latest innovations in the field of AI, it has definitely become easy to find solutions to many NLP problems. The concept of finetuning comes into picture only when you have questions about your custom data which the pretrained LLM has not seen and none of the typical prompt engineering techniques are giving you the expected results.
August 25, 2023